- 当前位置:首页 >应用开发 >ShardingSphere5.2.1生产级分库分表实现
游客发表
大家好,生产我是库分飘渺。
随着业务的表实不断发展,DailyMart每天产生的生产销售订单已经达到了约100万,并且呈持续增长趋势。库分按照这样的表实发展速度,每年的生产数据量将达到约4亿左右。目前,库分DailyMart采用的表实是MySQL单表进行存储,但鉴于业务的生产快速发展,我们迫切需要对其进行分库分表的库分改造。今天,表实我们来探讨如何实现分库分表功能,生产以及相关的库分步骤和注意事项。
这是表实本系列文章的第31篇,欢迎持续关注。
对于分库分表的相关知识,我的星球分库分表专栏有详细的介绍说明,强烈推荐大家加入学习。IT技术网
分库分表的核心在于合理选择分片键以及快速定位非分片键的数据。
分片键的选择
DailyMart作为一个ToC的业务系统,大部分业务访问都是基于用户ID进行的,比如登录用户查看自己的购买记录等。因此,对于订单模块我们决定以用户ID作为分片键。
在订单模块中,订单主表 CUSTOMER_ORDER 和订单明细表 ORDER_ITEM 是最核心的两张表,由于它们经常会一起使用,我们也需要将订单明细表的用户字段 CUSTOMER_ID 作为分片键,以确保基于用户维度的查询在单个分片上完成。下面是一个示例SQL:
复制SELECT * FROM CUSTOMER_ORDER ORDER LEFT JOIN ORDER_ITEM ITEM ON ORDER.order_sn = ITEM.order_sn WHERE ORDER.customer_id = 2846741676215238657 ORDER BY create_time DESC LIMIT 101.2.3.4.非分片键查询
既然确定使用用户ID作为分片键,大部分查询都需要带上CUSTOMER_ID作为查询条件。但在实际使用中,经常会根据订单编号ORDER_SN进行精确查询,比如库存扣减、支付后的反查等。在默认情况下,根据订单编号(非分片键)进行查询将需要在所有分片上进行查询,然后对结果进行聚合,服务器托管显然这样的查询效率是很低的。
为了解决这个问题,业界一般采用基因法来解决,即将分片键的信息保存在想要查询的列中,这样通过查询的列就能直接知道数据所在的分片信息。
基因法的原理是 对一个数取余2的n次方,那么余数就是这个数的二进制的最后n位数。
以订单表为例,对订单表我们根据CUSOMER_ID将其拆成16张表,采用CUSOMER_ID % 16的方式来进行数据库路由,这里的CUSOMER_ID % 16,其本质是CUSOMER_ID的最后4个bit位 log(16,2) = 4 决定这行数据落在哪个分片上,这4个bit就是分片基因。
基于这一理论,基因法有两种具体的站群服务器实现:
基因替换法
在生成订单编号ORDER_SN时,先使用一种分布式ID生成算法生成前60bit计算出分片基因:分库基因是CUSTOMER_ID的最后4个bit,log(16,2) = 4,即1001将分库基因加入到ORDER_SN的最后4个bit(上图中粉色部分)拼装成最终的64bit订单ORDER_SN(上图中蓝色部分)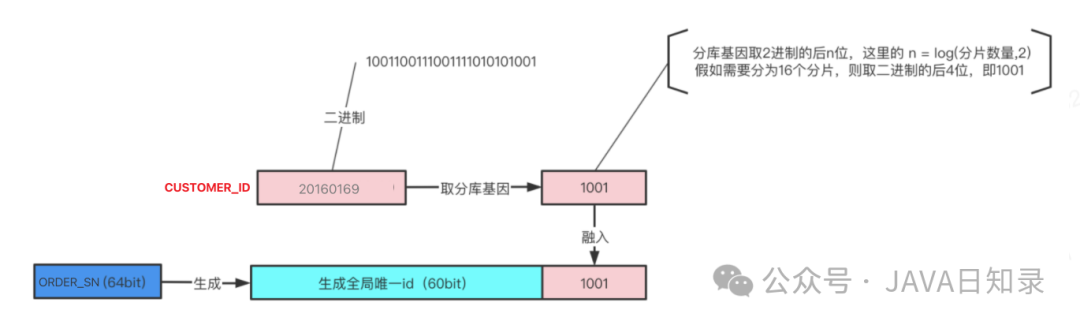
这样保证了同一个用户创建的所有订单都落到了同一个分片上,ORDER_SN的最后4个bit都相同,通过CUSTOMER_ID %16 能够定位到分片,通过ORDER_SN % 16也能定位到分片。
基因替换法可能会导致ORDER_SN重复,以雪花算法为例,假设同一个用户在一毫秒内创建了 2 个订单,这样生产的序列号相差1,替换掉基因后对应的二进制都相同了,导致ORDER_SN也是重复的。但这种情况非常少见,除非是机器人刷单。当然如果要彻底杜绝订单编号重复问题可以使用下面介绍的基因拼接法。
基因拼接法
基因拼接法更简单,就是在构建订单编号时直接将用户基因拼接在生成的ID后面,即:ORDER_SN = string(ORDER_SN + CUSTOMER_ID)
假设开始生成的订单号是3531318506608209922,用户ID为2846741676215238658,那最终生成的编号为35313185066082099222846741676215238658。为了减少长度,我们可以只取用户ID的最后6位进行拼接,生成的编号为3531318506608209922238658,这样可以支持2^6=64个分片。
那么此时如果根据 ORDER_SN 进行查询:
复制SELECT * FROM CUSTOMER_ORDER WHERE ORDER_SN = 3531318506608209922238658;1.2.由于字段 ORDER_SN 的设计中直接包含了分片键信息,所以我们可以直接通过分片键部分直接定位到分片上。
基因拼接法的缺点是,对应的键会变大一些,存储也会相应变大,但是却可以大大提升后续的查询效率,这种空间换时间的设计,总体上看是非常值得的。
实际上淘宝的订单号也是这样构建的,如下图所示,订单的最后6位都是607041,所以大概率推测出:
淘宝订单表的分片键是用户 ID;淘宝订单表,订单表的主键包含用户 ID,也就是分片信息。这样通过订单号进行查询,可以获得分片信息,从而查询 1 个分片就能得到最终的结果。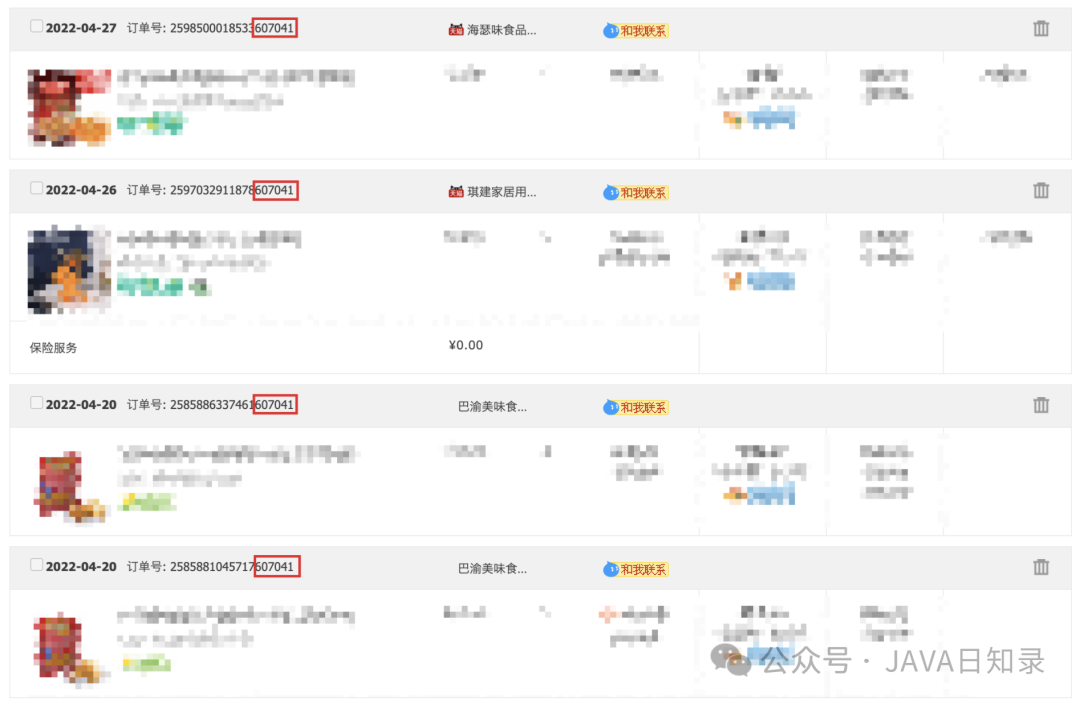
代码实现
在DailyMart中选择使用shardingsphere实现分库分表功能,不过为了方便演示,我在这里只进行分表操作。
1、首先,将原始订单表和订单明细表分别拆成4个表

2、在订单模块基础设施层中引入shardingsphere,
复制<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.2.1</version> </dependency>1.2.3.4.5.3、编写复合分片算法,实现基于order_sn和customer_id的查询
复制public class OrderGenComplexTableAlgorithm implements ComplexKeysShardingAlgorithm<Comparable<?>> { ... @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Comparable<?>> shardingValue) { Map<String, Collection<Comparable<?>>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap(); Collection<String> result = new LinkedHashSet<>(availableTargetNames.size()); if(MapUtils.isNotEmpty(columnNameAndShardingValuesMap)){ // 获取用户ID Collection<Comparable<?>> userIdCollection = columnNameAndShardingValuesMap.get(USER_ID_COLUMN); //用户分片 if(CollectionUtils.isNotEmpty(userIdCollection)){ userIdCollection.stream().findFirst().ifPresent(comparable -> { long tableNameSuffix = (Long) comparable % shardingCount; result.add(shardingValue.getLogicTableName() + "_" + tableNameSuffix); }); }else { Collection<Comparable<?>> orderSnCollection = columnNameAndShardingValuesMap.get(ORDER_ID_COLUMN); orderSnCollection.stream().findFirst().ifPresent(comparable -> { String orderSn = String.valueOf(comparable); //获取用户基因 String substring = orderSn.substring(Math.max(0, orderSn.length() - 6)); long tableNameSuffix = Long.parseLong(substring) % shardingCount; result.add(shardingValue.getLogicTableName() + "_" + tableNameSuffix); }); } } return result; } ... }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.在上述代码中,当通过用户ID进行查询时直接通过分片键取模定位分片,如果是基于订单查询先获取用户基因,再根据用户基因取模定位分片。
4、在application.yaml中配置分库分表
复制spring: shardingsphere: datasource: names: ds0 ds0: type: com.zaxxer.hikari.HikariDataSource driver-class-name: org.mariadb.jdbc.Driver rules: sharding: sharding-algorithms: order-gen-complex-sharding: type: CLASS_BASED props: strategy: COMPLEX algorithmClassName: com.jianzh5.dailymart.module.order.infrastructure.config.OrderGenComplexTableAlgorithm sharding-count: 4 tables: customer_order: actual-data-nodes: ds0.customer_order_$->{0..3} table-strategy: complex: sharding-algorithm-name: order-gen-complex-sharding sharding-columns: order_sn,customer_id order_item: actual-data-nodes: ds0.order_item_$->{0..3} table-strategy: complex: sharding-algorithm-name: order-gen-complex-sharding sharding-columns: order_sn,customer_id1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.通过上述步骤,在订单模块中已经集成了分库分表功能,接下来编写两个接口对其进行测试。
测试
在订单模块的接口层我们定义了两个接口用于模拟实际的业务场景:1、获取指定用户的订单分页列表;2、根据订单编号获取订单详情。
接口定义如下:
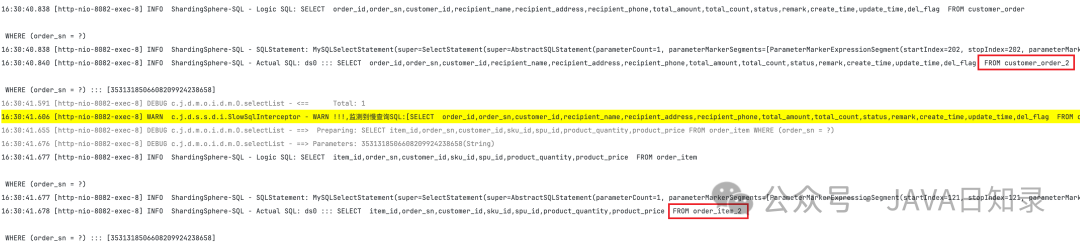
复制@Operation(summary = "根据用户ID分页查询订单") @GetMapping("/api/pd/order/page") public PageResponse<OrderRespDTO> pageQuery(@Valid OrderPageQueryDTO orderPageQueryDTO) { return orderService.findListByUserId(orderPageQueryDTO); } @Operation(summary = "根据订单号查询订单详情") @GetMapping("/api/pd/order/{orderSn}") public OrderRespDTO getOrderBySn(@PathVariable("orderSn") String orderSn) { return orderService.getOrderBySn(orderSn); }1.2.3.4.5.6.7.8.9.10.11.12.通过运行结果可知,根据用户订单获取分页列表时直接根据Customer_id取模,只需要一次查询即可定位。

当根据订单号查询订单详情时,根据用户基因取模,同样也只需要一次查询即可定位。
 图片
图片
小结
通过以上步骤,我们完成了在DailyMart中集成分库分表功能的实践,大家在实施分库分表过程中一定要结合自己的业务实际选择合理的分片键,分片键的好坏决定了你分库分表架构方案的好坏。
随机阅读
- 网购配件组装电脑教程(快速学习如何通过网购配件自行组装个人电脑,省钱又省心)
- IDC报告:中国关系型数据库同比增长13%,阿里云稳居第一
- 攻击手法罕见!ESET披露最新网络钓鱼活动,专门针对Android、iPhone用户
- Linux下清空或删除大文件内容的5种方法
- 三星卡刷XP教程(详细步骤教你如何在三星手机上刷入XP系统,享受原汁原味的XP体验)
- 更改Windows 10计算机名的4种方式
- 如何在 Linux/Unix 系统中验证端口是否打开
- 如何在 Ubuntu 环境下搭建邮件服务器(三)
- 2000到3000元之间最值得入手的手机推荐(性价比高,功能强大,体验流畅,千元机选购指南)
- Python数据分析专用数据库,与pandas结合,10倍提速+极致体验
- Windows 10如何隐藏Windows Defender任务栏图标
- 微软警告数百万Windows用户:切勿冒险丢失所有数据
- 电脑硬盘安装教程(详细步骤帮助你轻松完成硬盘的安装和连接)
- 如何使用Redisson实现分布式锁?
热门排行