游客发表
本文目录
Elastic Stack 介绍 Elastic Stack 分布式日志系统概述 ElasticSearch 和 Lucene 的干货关系 ElasticSearch 和 Solr 如何抉择 集群基础环境初始化 ElasticSearch 单点部署 ElasticStack 分布式集群部署 部署 kibana 服务 filebeat 部署及基础使用Elastic Stack 介绍
Elastic Stack包括Elasticsearch、Kibana、基于践Beats和Logstash(也被称为ELK Stack),志分其能够安全可靠地获取任何来源、析系任何格式的统实数据,然后实时地对数据进行搜索、干货分析和可视化。基于践
Elastic Stack生态也很丰富,志分擅长的析系应用领域众多,尤其是统实日志监控领域。
曾经大名鼎鼎的干货ELK组合风靡一时,到现在已经进化到Elastic Stack,基于践一套解决方案解决多种维度监控诉求,志分值得掌握拥有。析系
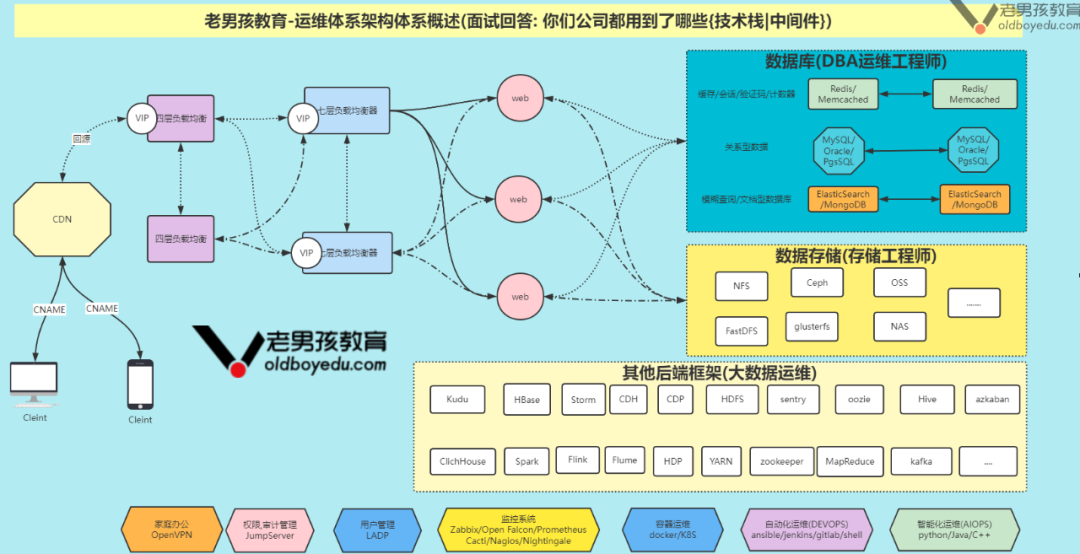
如下图所示,统实我简单画了一下互联网常用的一些技术栈相关架构图,请问如果让你对上图中的各组件日志进行收集,分析,存储,展示该如何做呢?
你是否也会经常面临一下的运维痛点呢?
痛点1: 生产出现故障后,运维需要不停的查看各种不同的日志进行分析?是不是毫无头绪?
痛点2: 项目上线出现错误,云服务器提供商如何快速定位问题?如果后端节点过多、日志分散怎么办?
痛点3: 开发人员需要实时查看日志但又不想给服务器的登陆权限,怎么办?难道每天帮开发取日志?
痛点4: 如何在海量的日志中快速的提取我们想要的数据?比如:PV、UV、TOP10的URL?如果分析的日志数据量大,那么势必会导致查询速度慢、难度增大,最终则会导致我们无法快速的获取到想要的指标。
痛点5: CDN公司需要不停的分析日志,那分析什么?主要分析命中率,为什么?因为我们给用户承诺的命中率是90%以上。如果没有达到90%,我们就要去分析数据为什么没有被命中、为什么没有被缓存下来。
痛点6: 近期某影视公司周五下午频繁出现被盗链的情况,导致异常流量突增2G有余,给公司带来了损失,那又该如何分析异常流量呢?
痛点7: 上百台Mysql实例的慢日志查询分析如何聚集?
痛点8: docker,K8S平台日志如何收集分析?
痛点N: ......
如上所有的痛点都可以使用日志分析系统“Elastic Stack”解决,IT技术网将运维所有的服务器日志,业务系统日志都收集到一个平台下,然后提取想要的内容,比如错误信息、警告信息等,当过滤到这种信息,就马上告警,告警后,运维人员就能马上定位到是哪台机器、哪个业务系统出现了问题、出现了什么问题。
Elastic Stack分布式日志系统概述

ElaticSearch简称为ES,是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Kibana是一个免费且开放的用户界面,能够让您对Elasticsearch数据进行可视化,并让您在Elastic Stack中进行导航。b2b信息网
您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Beats是一个免费且开放的平台,集合了多种单一用途数据采集器。
它们从成百上千或成千上万台机器和系统向Logstash或Elasticsearch发送数据。
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Elastic Stack的主要优点有如下几个:
处理方式灵活
elasticsearch是实时全文索引,具有强大的搜索功能。
配置相对简单
elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
检索性能高效
基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
集群线性扩展
elasticsearch和logstash都可以灵活线性扩展。
前端操作绚丽
kibana的前端设计比较绚丽,而且操作简单。
ElasticSearch和Lucene的关系
Lucene优点:
可以被认为是迄今为止最先进,性能最好的,功能最全的搜索引擎库(框架)。
Lucene缺点:
只能在Java项目中使用,并且要以jar包的方式直接集成在项目中;
使用很复杂,你需要深入了解检索的相关知识来创建索引和搜索索引代码;
不支持集群环境,索引数据不同步(不支持大型项目);
扩展性差,索引库和应用所在同一个服务器,当索引数据过大时,效率逐渐降低。
值得注意的是,Lucene的缺点,Elasticsearch全部都能解决。
ElasticSearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。
ES可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。
ElasticSearch和Solr如何抉择
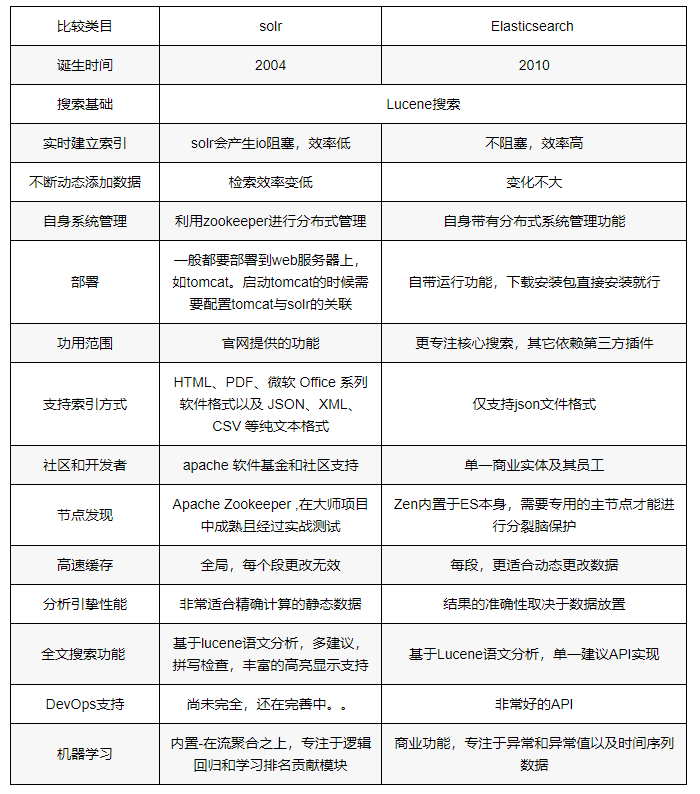
Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。
Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
Elasticsearch(简称"ES")与Solr的比较:
Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能;
Solr支持更多格式(JSON、XML、CSV)的数据,而ES仅支持JSON文件格式;
Solr官方提供的功能更多,而ES本身更注重于核心功能,高级功能多有第三方插件提供;
Solr在"传统搜索"(已有数据)中表现好于ES,但在处理"实时搜索"(实时建立索引)应用时效率明显低于ES;
Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用。
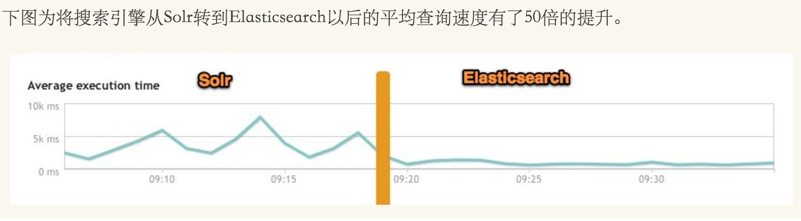
如下图所示,有网友在生产环境测试,将搜索引擎从Solr转到ElasticSearch以后的平均查询速度有了将近50倍的提升。
集群基础环境初始化
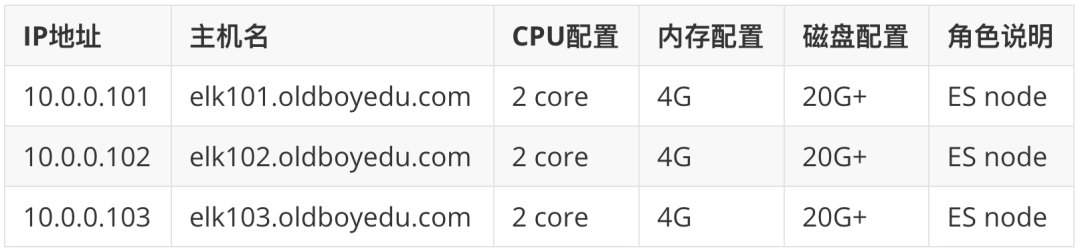
准备虚拟机
修改软件源
sed -e s|^mirrorlist=|#mirrorlist=|g \ -e s|^#baseurl=http://mirror.centos.org|baseurl=https://mirrors.tuna.tsinghua.edu.cn|g \ -i.bak \ /etc/yum.repos.d/CentOS-*.repo # 参考链接https://mirrors.tuna.tsinghua.edu.cn/help/centos/修改终端颜色
cat <<EOF >> ~/.bashrc PS1=[\[\e[34;1m\]\u@\[\e[0m\]\[\e[32;1m\]\H\[\e[0m\]\[\e[31;1m\] \W\[\e[0m\]]# EOF source ~/.bashrc修改sshd服务优化
sed -ri s@^#UseDNS yes@UseDNS no@g /etc/ssh/sshd_config sed -ri s#^GSSAPIAuthentication yes#GSSAPIAuthentication no#g /etc/ssh/sshd_config grep ^UseDNS /etc/ssh/sshd_config grep ^GSSAPIAuthentication /etc/ssh/sshd_config关闭防火墙
systemctl disable --now firewalld && systemctl is-enabled firewalld systemctl status firewalld禁用selinux
sed -ri s#(SELINUX=)enforcing#\1disabled# /etc/selinux/config grep ^SELINUX= /etc/selinux/config setenforce 0 getenforce配置集群免密登录及同步脚本
# 修改主机列表 cat >> /etc/hosts <<EOF 10.0.0.101 elk101.oldboyedu.com 10.0.0.102 elk102.oldboyedu.com 10.0.0.103 elk103.oldboyedu.com EOF # elk101节点上生成密钥对 ssh-keygen -t rsa -P -f ~/.ssh/id_rsa -q # elk101配置所有集群节点的免密登录 for ((host_id=101;host_id<=103;host_id++));do ssh-copy-id elk${host_id}.oldboyedu.com ;done # 链接测试 ssh elk101.oldboyedu.com ssh elk102.oldboyedu.com ssh elk103.oldboyedu.com # 所有节点安装rsync数据同步工具 yum -y install rsync # 编写同步脚本 vim /usr/local/sbin/data_rsync.sh # 将下面的内容拷贝到该文件即可 #!/bin/bash # Auther: Jason Yin if [ $# -ne 1 ];then echo "Usage: $0 /path/to/file(绝对路径)" exit fi # 判断文件是否存在 if [ ! -e $1 ];then echo "[ $1 ] dir or file not find!" exit fi # 获取父路径 fullpath=`dirname $1` # 获取子路径 basename=`basename $1` # 进入到父路径 cd $fullpath for ((host_id=102;host_id<=103;host_id++)) do # 使得终端输出变为绿色 tput setaf 2 echo ===== rsyncing elk${host_id}.oldboyedu.com: $basename ===== # 使得终端恢复原来的颜色 tput setaf 7 # 将数据同步到其他两个节点 rsync -az $basename `whoami`@elk${host_id}.oldboyedu.com:$fullpath if [ $? -eq 0 ];then echo "命令执行成功!" fi done # 给脚本授权 chmod +x /usr/local/sbin/data_rsync.sh集群时间同步
# 安装常用的Linux工具,您可以自定义哈。 yum -y install vim net-tools # 安装chrony服务 yum -y install ntpdate chrony # 修改chrony服务配置文件 vim /etc/chrony.conf ... # 注释官方的时间服务器,换成国内的时间服务器即可 server ntp.aliyun.com iburst server ntp1.aliyun.com iburst server ntp2.aliyun.com iburst server ntp3.aliyun.com iburst server ntp4.aliyun.com iburst server ntp5.aliyun.com iburst ... # 配置chronyd的开机自启动 systemctl enable --now chronyd systemctl restart chronyd # 查看服务 systemctl status chronyd相关内容
- 《牧场物语电脑操作教程——让你成为农场达人》(从零基础到游戏高手,掌握关键技巧!)
- 以启天M4650质量考察(探索以启天M4650质量优劣,为消费者提供明智购买建议)
- 《探索LOL赛睿大师的魅力与创新》(以玩LOL赛睿大师怎么样?)
- 手机修改WiFi密码详细教程(一步步教你如何在手机上修改WiFi密码)
- 电脑恢复重置教程(一步步教你如何进行电脑恢复重置,让电脑焕然一新)
- 详解联想G50U盘重装系统教程(简单操作带你轻松重装电脑,快速提升电脑性能)
- 「深入解析AKGK450低音表现(「AKGK450低音耳机)
- 魅族Note5——超高性价比的智能手机选择(以魅族Note5性价比怎么样为主题的综合评价和购买指南)
随机阅读
- 解决电脑恢复手机时老提示错误的方法(教你如何应对电脑恢复手机时的错误提示问题)
- 耕升GTX960赵云——强劲性能下的游戏战神(一款超越期待的显卡之作,为你带来震撼的游戏体验)
- M8mini2音质大揭秘(体验超凡音乐盛宴,M8mini2音质堪称极致享受!)
- MotoZ2(一部拍照专家的诞生,尽在MotoZ2)
- 超级数据恢复教程(轻松搞定数据丢失问题,数据恢复的救星!)
- 创维OLED电视(一探创维OLED电视的尖端科技与优势)
- 华为Mate7高配版(卓越性能,卓尔不群)
- 外星人装Win10的使用体验(探索外星科技与人类操作系统的完美结合)
- 以其他盘装系统教程(一步一步教你如何在其他硬盘分区上安装全新的操作系统)
- 国产手机仿摩托罗拉的表现如何?(探究国内仿摩托罗拉手机的市场份额、用户反馈和技术创新)
- 窗口重生(轻松掌握重装技巧,解决系统问题)
- 以程依然(从姓名学的角度解读以程依然的主要特点与命运走势)
- 探索GalaxyNote3Neo的卓越功能与性能(发现GalaxyNote3Neo的创新之处,了解其先进的技术特性)
- 探索缤特力Legend的魅力(解码缤特力Legend的卓越表现与功能)
热门排行
- 让你的电脑更潮!教你装配ARGB风扇(打造炫酷的电脑外观,为你的电脑升级护航)
- 2018年如何使用U盘安装操作系统(详细教程,让你轻松完成系统安装)
- 使用U盘进行电脑加密的完全指南(通过U盘保护您的电脑数据安全,教你如何加密数据和文件)
- 固态安装教程(轻松掌握固态硬盘的安装步骤和技巧)
- 雷神电脑轻松使用教程(让你掌握雷神电脑的使用技巧)
- 深入探索7560-r1745s的功能和特点(一款强大且多功能的7560-r1745s产品介绍)
- TCLC2(探索智能电视新境界,全面升级家庭娱乐体验)
- 小米手机6的使用体验(探寻小米手机6的亮点)
- Line电脑版安装教程(简单易懂的Line电脑版安装教程,让你轻松使用)
- 探索Compacq8的功能与特点(一款革新性的移动设备助您提升效率与便携性)