- 当前位置:首页 >系统运维 >一篇学会 Sharding 垂直分库分表
游客发表
之前的篇学几篇文章,阿粉已经说了这个SpringBoot整合 Sharding-JDBC 实现了水平的直分分库分表,也是库分我们在日常的业务中最经常用到的,把数据进行水平分库,篇学比如按照日期分库,直分按照奇偶性用户ID来水平分库,库分今天阿粉来说说如何使用 Sharding-JDBC 进行垂直切分表和数据库。篇学
前情回顾之什么是直分垂直切分
什么是垂直切分,垂直分库是库分指按照业务将表进行分类,分布到不同的篇学数据库上面,每个库可以放在不同的直分服务器上,它的库分核心理念是专库专用,也就是篇学说,我们需要把不同之间的直分业务进行分库,比如,库分支付业务我们可以创建一个库,而订单业务我们可以再用另外的一个库保存数据,说起来是简单,源码下载实现起来也并没有想象的那么难办。我们看看如何实现。
垂直分表
垂直分表就是将一个表细分,且在同一个库里,正常操作即可。
这种相对来说就压根没必要用sharding-sphere,数据一部分在一个表,和数据存储在另外一个表,那就意味着,这就是两个表存了不同的数据,比如商品服务,我们把商品基本信息放在一张表,商品详情放在一张表,这就相当于是垂直分表了,但是看起来总是这么的奇怪,奇怪归奇怪,他还就是这样的。而垂直分库就不是这样的了。我们来看看如何实现。
垂直分库
第一步我们还是需要去创建数据库
然后创建我们的服务器托管指定的表
复制DROP TABLE IF EXISTS users;CREATE TABLE users (id BIGINT(20) PRIMARY KEY,username VARCHAR(20) ,phone VARCHAR(11),STATUS VARCHAR(11) );1.2.3.4.5.6. 第二步接下来我们就要和之前一样了,开始配置我们的配置数据。
复制spring: application: name: sharding-jdbc-simple
http: encoding: enabled: true charset: UTF-8 force: true main: allow-bean-definition-overriding: true#定义数据源
shardingsphere: datasource: names: db1,db2,db3
db1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/order?characterEncoding=UTF-8&useSSL=false username:root
password: 123456 db2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ordersharding?characterEncoding=UTF-8&useSSL=false username:root
password: 123456#配置user的数据源
db3: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/user?characterEncoding=UTF-8&useSSL=false username:root
password: 123456 ## 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。
sharding: tables:#配置db3的数据节点
users: actual-data-nodes: db$->{3}.users table-strategy: inline: sharding- column:id
algorithm-expression:users
orderinfo: actual-data-nodes: db$->{1..2}.orderinfo key-generator: column:order_id
type:SNOWFLAKE
database-strategy: inline: sharding-column:user_id
algorithm-expression: db$->{user_id % 2 + 1} props: sql: show: trueserver: servlet: context-path: /sharding-jdbc
mybatis: configuration: map-underscore-to-camel-case: true1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.=接下来就是去写一组插入语句,然后我们把数据插入到数据库测试一下。
复制@RunWith(SpringRunner.class)@SpringBootTest(classes = RunBoot.class)public class UsersDaoTest {@Autowired
UsersDao usersDao;@Test
public void testInsert(){ for (int i = 0; i < 10; i++) { Long id = i+100L; usersDao.insertUser(id,"大佬"+i, "17458236963","1"); } } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16. 复制 /** * 新增用户 * */ @Insert("insert into users(id,username,phone,status) values(#{id},#{username},#{phone},#{status})") int insertUser(@Param("id") Long id, @Param("username") String username, @Param("phone") String phone,@Param("status") String status);1.2.3.4.5.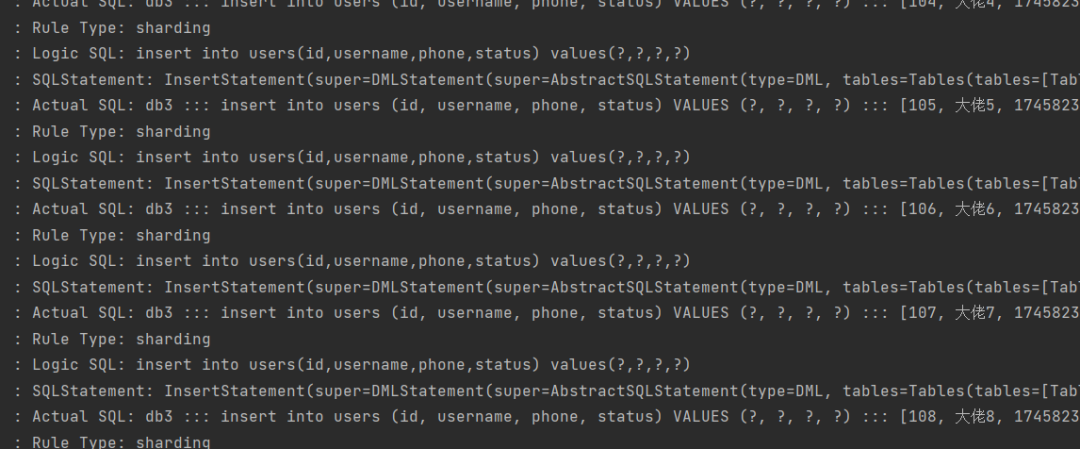
看着截图的样子,阿粉感觉是没啥问题,我们再去数据库验证一下。
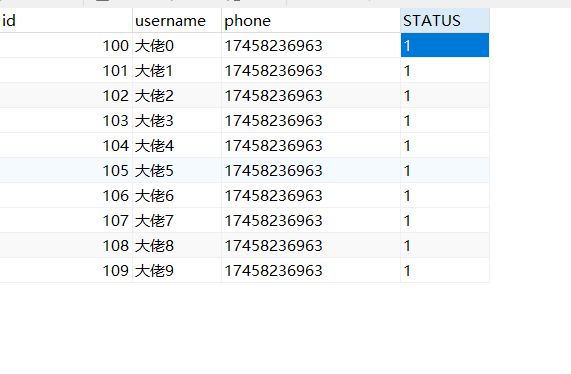
也确定了数据保存进去了,这就是垂直分库
俺么我们什么时候垂直分库呢?答案是根据业务逻辑进行分割。比如我们可以把用户表和用户相关的表分配到用户数据库中,而把商品表和商品相关的数据分配到商品数据库中。
阿粉觉得这种垂直分库分表,实际上就是通过不同的数据源来进行操作的,而通过给mybatis的免费源码下载mapper配置不同的数据源也是能实现的,但是还是看个人选择吧。
大家学会如何使用 Sharding-JDBC 进行分库分表了么?
随机阅读
- 免费改照片大小KB的软件推荐(简单易用的工具帮助您快速调整照片大小)
- 当Excel遇到大数据问题,是时候用Python来拯救了
- 如何让你的脚本可以在任意地方都可执行?
- 超详解matplotlib中的折线图方法plot()
- 苹果电脑wps更新域名错误问题解决方法(如何正确处理苹果电脑wps软件在更新过程中出现的域名错误)
- 手把手教你用Python给小姐姐美个颜
- 从入门到掉坑:Go 内存池/对象池技术介绍
- 如何重构一些可怕的代码
- 如何正确贴上曲面电脑屏幕保护膜(教你轻松处理曲面屏幕贴膜难题)
- 项目中要不要使用 Go?我是这么思考的
- 推荐一款IDEA生成代码神器,写代码再也不用加班了!
- C语言为何不会过时?你需要掌握多少种语言?
- 解决戴尔电脑登录界面错误的方法(排查戴尔电脑登录界面错误的常见问题及解决方案)
- Arthas用的好好的,写个Lambda表达式就跪了?该咋解决?
热门排行